IA locale gratuite avec Ollama et LM Studio (guide 2026)
IA locale avec Ollama et LM Studio : installation (CLI, Docker), meilleurs modèles 2026 et usages concrets. Gratuit, privé, hors ligne.
Pourquoi continuer à payer ChatGPT ? Installez une IA gratuite sur votre PC en 10 minutes
Vous payez 20 euros par mois pour ChatGPT Plus. Peut-être même 20 euros de plus pour Claude Pro. Et vous envoyez toutes vos données — vos textes, vos idées, vos documents confidentiels — sur les serveurs de quelqu’un d’autre.
Il existe une alternative : l’IA locale. Installer des modèles d’IA open-source directement sur votre machine. Gratuit. Privé. Et cela fonctionne même sans connexion.
Je le sais parce que je l’ai découvert par nécessité. J’utilisais ChatGPT et Claude plus de 100 fois par jour. Puis j’ai eu un vol de 9 heures pour l’Inde. Pas de WiFi. Et là, j’ai réalisé à quel point j’étais dépendant d’un service en ligne.
Depuis, j’ai installé des LLM en local. Et honnêtement, pour 80% de mes usages quotidiens, cela répond au besoin. Si vous cherchez d’abord à explorer les options gratuites avant de passer au local, consultez mon comparatif des meilleurs outils IA gratuits en 2026.
La vidéo complète
IA propriétaire vs open-source : comprendre la différence en 30 secondes
Avant de plonger dans les outils, il faut comprendre une distinction fondamentale.
| IA propriétaire | IA open-source | |
|---|---|---|
| Exemples | ChatGPT, Claude, Gemini | Mistral, Llama 3.1, DeepSeek |
| Où ça tourne | Sur leurs serveurs | Sur votre machine |
| Prix | 20-25 euros/mois | Gratuit |
| Confidentialité | Vos données transitent par leurs serveurs | Vos données ne quittent jamais votre PC |
| Internet requis | Oui | Non |
Selon Hugging Face, la plateforme héberge désormais plus de 2 millions de modèles open-source, contre 1 million un an plus tôt — le second million a été atteint en seulement 335 jours. Le mouvement open-source en IA n’est pas une niche — c’est une tendance de fond.
 Ollama et LM Studio : deux outils gratuits et complémentaires pour l’IA locale.
Ollama et LM Studio : deux outils gratuits et complémentaires pour l’IA locale.
Ollama : installer un LLM en local en 2 minutes
Ollama est l’outil le plus simple pour faire tourner des modèles d’IA en local. C’est un outil en ligne de commande, mais ne vous inquiétez pas — c’est aussi simple que d’installer une app.
Installation
- Rendez-vous sur ollama.com
- Téléchargez et installez
- Ouvrez votre terminal et tapez :
ollama run mistralC’est tout. Ollama télécharge le modèle Mistral 7B (~4 Go) et vous pouvez commencer à discuter directement dans le terminal.
Commandes essentielles
ollama run mistral— lancer Mistral en mode chatollama run llama3— lancer Llama 3 de Metaollama run deepseek-r1— lancer DeepSeek R1ollama ls— lister tous les modèles installés sur votre machineollama pull gemma3— télécharger un modèle sans le lancer
Ollama Docker : déployer l’IA locale sur un serveur
Si vous souhaitez déployer Ollama sur un serveur (VPS, NAS, machine partagée), Docker est la méthode recommandée. Une commande suffit :
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollamaPour les machines avec GPU NVIDIA, ajoutez --gpus=all pour activer l’accélération matérielle. Le port 11434 expose l’API REST d’Ollama, compatible avec le format OpenAI.
Téléchargez un modèle dans le conteneur :
docker exec -it ollama ollama pull mistralPour un déploiement avec Docker Compose (recommandé en production) :
services:
ollama:
image: ollama/ollama
ports:
- "11434:11434"
volumes:
- ollama_data:/root/.ollama
restart: unless-stopped
volumes:
ollama_data:L’avantage d’Ollama avec Docker : vous déployez l’IA locale sur n’importe quelle machine Linux en moins de 5 minutes, et vos modèles persistent entre les redémarrages grâce au volume monté. C’est la configuration que j’utilise pour connecter Ollama à n8n sur mon serveur.
Ajouter une interface graphique à Ollama
Le terminal, c’est bien. Mais si vous voulez une vraie interface de chat, voici les options :
- Enchanted — app native Apple, élégante et rapide (iOS, iPadOS, macOS, visionOS)
- Open WebUI — interface web auto-hébergée, la plus complète
- MSTY — multiplateforme, simple à installer
- LibreChat — open-source, interface similaire à ChatGPT
LM Studio : l’alternative tout-en-un avec interface graphique
Si vous n’aimez pas le terminal, LM Studio est fait pour vous. C’est une application de bureau qui fait tout :
- Bibliothèque de modèles — télécharge directement depuis l’app
- Interface de chat — comme ChatGPT, mais en local
- Serveur API — expose une API compatible OpenAI pour vos outils
- Métriques de performance — affiche les tokens/seconde en temps réel
LM Studio fonctionne sur Mac, Windows et Linux. L’interface est soignée, et le mode “Power User” donne accès à des réglages avancés (température, top-p, contexte).
Quel modèle choisir selon votre besoin
Selon le Stanford HAI AI Index Report 2025, l’écart de performance entre modèles open-weight et propriétaires est passé de 8% à seulement 1,7% en un an sur le Chatbot Arena Leaderboard. Les modèles open-source rivalisent désormais avec les meilleurs modèles fermés.
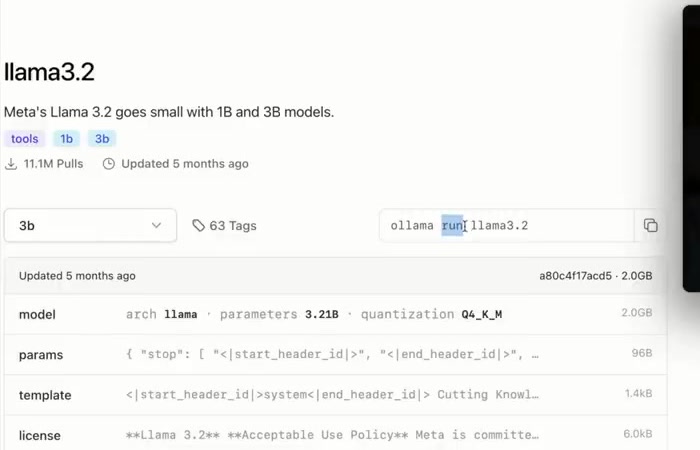
Les modèles Ollama les plus populaires en 2026
Ollama donne accès à des centaines de modèles open-source. Voici les plus téléchargés :
| Modèle Ollama | Taille | VRAM requise | Force principale |
|---|---|---|---|
| Mistral 7B | 4,1 Go | 8 Go | Performant en français (Mistral AI), rapide |
| Llama 3.1 8B | 4,7 Go | 8 Go | Polyvalent, très bon en anglais |
| Gemma 3 4B | 3,3 Go | 6 Go | Multimodal (images + texte), léger |
| DeepSeek R1 7B | 4,7 Go | 8 Go | Raisonnement avancé |
| Qwen 2.5 Coder 7B | 4,7 Go | 8 Go | Génération et analyse de code |
| Phi-4 Mini 3.8B | 2,4 Go | 4 Go | Ultra-léger, machines modestes |
| Llava 7B | 4,5 Go | 8 Go | Analyse d’images et captures d’écran |
| nomic-embed-text | 274 Mo | 1 Go | Embeddings pour le RAG |
Pour installer n’importe quel modèle : ollama pull nom-du-modele. La commande ollama ls liste tous les modèles installés sur votre machine. Pour un comparatif détaillé avec benchmarks et cas d’usage par catégorie, consultez mon guide des meilleurs modèles Ollama en 2026.
Pour un assistant généraliste
- Mistral 7B — performant en français, léger (4 Go), rapide. C’est mon choix par défaut.
- Gemma 3 (Google) — très bon en raisonnement, fonctionne bien en multilingue.
Pour analyser des images et des PDF
- Llava ou Gemma 3 Vision — modèles multimodaux capables de comprendre des images, des captures d’écran, des PDF.
Pour le code
- DeepSeek Coder ou Qwen 2.5 Coder — optimisés pour la génération et l’analyse de code.
Pour la recherche documentaire (RAG)
- Modèles d’embedding (nomic-embed, mxbai-embed) — transforment vos documents en vecteurs pour la recherche sémantique. Indispensable pour construire un “ChatGPT privé” sur vos propres fichiers.
 Le modèle 7B (Mistral, Gemma 3) offre le meilleur rapport performance/accessibilité avec seulement 8 Go de VRAM.
Le modèle 7B (Mistral, Gemma 3) offre le meilleur rapport performance/accessibilité avec seulement 8 Go de VRAM.
Configuration matérielle : ce dont vous avez vraiment besoin
Le facteur numéro un, c’est la VRAM — la mémoire de votre GPU. Pas la RAM classique, la VRAM.
| Taille du modèle | VRAM nécessaire | Exemple de GPU |
|---|---|---|
| 3B paramètres | ~4 Go | GTX 1650, Mac M1 8 Go |
| 7B paramètres | ~8 Go | RTX 3060, Mac M2 16 Go |
| 13B paramètres | ~16 Go | RTX 4070, Mac M2 Pro 32 Go |
| 70B paramètres | ~48 Go | RTX 4090 x2, Mac Studio 96 Go |
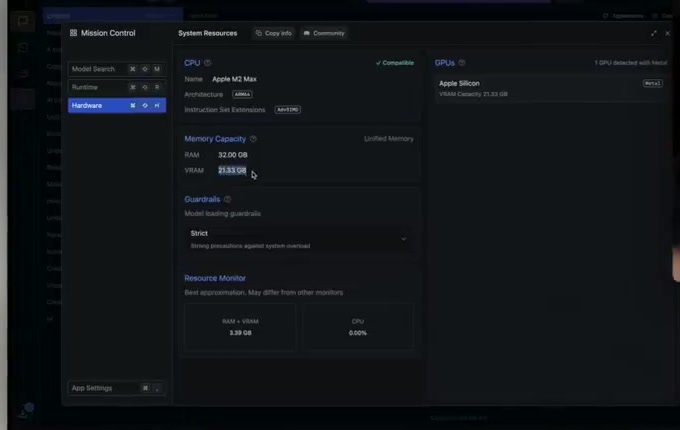
Le bon plan : le Mac Mini M2/M4 est excellent pour l’IA locale. La mémoire unifiée fait que toute la RAM est accessible au GPU. Un Mac Mini avec 16 Go fait tourner des modèles 7B sans problème.
 Un LLM local comme hub central connecté à 5 usages concrets — 100% gratuit et privé.
Un LLM local comme hub central connecté à 5 usages concrets — 100% gratuit et privé.
Usages avancés : là où ça devient vraiment intéressant
Automatisations confidentielles avec n8n + Ollama
Vous connaissez peut-être n8n pour les automatisations. Ce que beaucoup ne savent pas, c’est que vous pouvez connecter n8n directement à Ollama — le tout en local, sur votre machine.
Résultat : des workflows d’automatisation IA où vos données ne quittent jamais votre ordinateur. Pour aller encore plus loin dans l’automatisation avec des agents IA, consultez notre guide pour créer votre premier agent IA.
C’est un avantage décisif pour :
- Les cabinets d’avocats qui traitent des données clients sensibles
- Les professionnels de santé soumis au RGPD
- Toute entreprise manipulant des documents confidentiels
LM Studio + API + ngrok : connecter l’IA locale au cloud
LM Studio expose un serveur API compatible OpenAI. Combinez cela avec un tunnel ngrok, et vous pouvez connecter votre IA locale à des outils cloud comme Make ou Zapier. Pour comprendre comment les protocoles de connectivité IA fonctionnent, découvrez notre article sur le protocole MCP.
Concrètement : vous gardez le contrôle de vos données (le modèle tourne chez vous), tout en profitant des automatisations cloud.
Coder avec une IA locale gratuite (alternative à Cursor)
Dans VS Code, installez l’extension Continue. Connectez-la à Ollama. Vous avez maintenant un assistant de code IA — comme Cursor ou GitHub Copilot — mais 100% gratuit et 100% local.
Selon Gartner, 75% des développeurs en entreprise utiliseront des assistants de code IA d’ici 2028, contre moins de 10 % début 2024. Si vous codez, l’IA locale est une évidence économique.
Private GPT : un ChatGPT privé pour vos documents
Vous voulez interroger vos PDF, vos contrats, vos notes — sans que cela passe par OpenAI ? Des outils comme PrivateGPT utilisent le RAG (Retrieval Augmented Generation) pour créer un chatbot sur vos propres documents, 100% en local.
Super Whisper : transcription vocale locale
Pour transcrire votre voix en texte, Super Whisper utilise le modèle Whisper d’OpenAI — mais en local. Pas besoin d’internet, pas de données envoyées. Idéal pour dicter des notes, transcrire des réunions, ou créer du contenu.
Par où commencer (plan d’action en 15 minutes)
- Minute 0-5 — Installez Ollama depuis ollama.com
- Minute 5-8 — Lancez
ollama run mistraldans votre terminal - Minute 8-12 — Testez avec un vrai use case (reformuler un email, résumer un texte, brainstormer)
- Minute 12-15 — Si vous voulez une interface graphique, installez LM Studio
C’est tout. En 15 minutes, vous avez une IA gratuite, privée, qui tourne sur votre machine. Vous n’avez plus besoin d’internet. Vous n’avez plus besoin de payer 20 euros par mois. Et vos données restent chez vous.
Mon vrai avis
Est-ce que l’IA locale remplace ChatGPT ou Claude à 100% ? Non. Pour les tâches complexes (raisonnement long, gros contexte, dernières connaissances), les modèles propriétaires restent meilleurs.
Mais pour 80% des usages quotidiens — reformuler un texte, résumer un document, brainstormer, coder, automatiser — un Mistral 7B en local répond au besoin. Gratuitement. En privé. Et même dans un avion à 10 000 mètres d’altitude.
Vous voulez aller plus loin avec l’IA locale ? Ma newsletter vous envoie chaque semaine un système concret à implémenter. Pas de la théorie — de l’action.
Questions fréquentes
Comment utiliser l'IA gratuitement sans payer ChatGPT ?
Vous pouvez installer des LLM open-source comme Mistral, Llama 3.1 ou DeepSeek directement sur votre ordinateur avec Ollama (ligne de commande) ou LM Studio (interface graphique). C'est 100% gratuit, privé, et fonctionne même hors connexion.
Quelle configuration PC faut-il pour faire tourner une IA en local ?
Le facteur clé est la VRAM (mémoire du GPU). Un modèle 7B paramètres nécessite environ 8 Go de VRAM. Un Mac avec mémoire unifiée (Mac Mini M2 par exemple) est idéal car la RAM est partagée entre CPU et GPU.
Quelle est la différence entre Ollama et LM Studio ?
Ollama est un outil en ligne de commande, léger et rapide à installer. LM Studio propose une interface graphique complète avec bibliothèque de modèles intégrée, chat et serveur API. Les deux sont gratuits et complémentaires.
Quel modèle IA open-source choisir pour un usage en français ?
Mistral 7B est le modèle que je recommande pour le français — c'est un modèle créé par une entreprise française, optimisé pour notre langue. Gemma 3 de Google est une excellente alternative pour les tâches multimodales (images, PDF).
Peut-on utiliser une IA locale pour des données confidentielles en entreprise ?
Oui, c'est justement l'un des principaux avantages. Avec Ollama + n8n en local, vos données ne quittent jamais votre machine. C'est idéal pour les cabinets d'avocats, les professionnels de santé, ou toute entreprise manipulant des données sensibles.
Comment installer Ollama avec Docker ?
Exécutez docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama dans votre terminal. Cette commande lance Ollama en arrière-plan avec un volume persistant pour vos modèles. Ajoutez --gpus=all pour l'accélération GPU sur les machines NVIDIA.
Quels sont les meilleurs modèles Ollama en 2026 ?
Les modèles Ollama les plus populaires sont Mistral 7B (meilleur en français), Llama 3.1 8B (polyvalent), Gemma 3 (multimodal), DeepSeek R1 (raisonnement) et Qwen 2.5 Coder (code). La commande ollama pull nom-du-modele télécharge n'importe quel modèle en quelques minutes.
Qu'est-ce que l'IA locale ?
L'IA locale désigne l'exécution de modèles de langage (LLM) directement sur votre ordinateur, sans connexion internet ni envoi de données à des serveurs externes. Avec des outils comme Ollama et LM Studio, vous faites tourner des modèles open-source (Mistral, Llama, DeepSeek) gratuitement et en toute confidentialité.